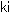Wed, Mar 3 AM
09:00 - 09:50 |
(1)
US |
09:00-09:25 |
Transmission characteristics of low profile airborne ultrasonic transducer |
Kohei Shida, Yuji Wada, Kentaro Nakamura (Tokyo Tech) |
(2)
US |
09:25-09:50 |
Fundamental study of trace-moisture inverse gas chromatography using ball surface acoustic wave sensor |
Toshihiro Tsuji, Yoshikazu Ohara, Tsuyoshi Mihara (Tohoku Univ.) |
| |
09:50-10:00 |
Break ( 10 min. ) |
Wed, Mar 3 AM
10:00 - 12:05 |
(3)
SIP |
10:00-10:25 |
A Constrained Alternating Minimization Approach to End-to-End Graph Signal Denoising |
Eisuke Yamagata, Shunsuke Ono (Titech) |
(4)
SIP |
10:25-10:50 |
Remote Sensing Data Restoration by Constraining the Gradients of Stripe Noise |
Kazuki Naganuma, Saori Takeyama, Shunsuke Ono (Titech) |
(5)
SIP |
10:50-11:15 |
Design of Graph Signal Sampling Matrices for Arbitrary Signal Subspaces |
Junya Hara, Koki Yamada (TUAT), Shunsuke Ono (TIT), Yuichi Tanaka (TUAT) |
(6)
SIP |
11:15-11:40 |
Automatic Detection of Epileptic Abnormal EEG Using Deep Learning |
Taku Shoji (TUAT), Noboru Yoshida (Juntendo Univ.), Toshihisa Tanaka (TUAT) |
(7)
SIP |
11:40-12:05 |
Estimation of Imagined Rhythm and Its Active Area from Electroencephalogram Using Deep Learning |
Naoki Yoshimura, Toshihisa Tanaka (TUAT) |
| |
12:05-13:05 |
Lunch Break ( 60 min. ) |
Wed, Mar 3 PM
13:05 - 13:55 |
(8)
EA |
13:05-13:55 |
[Invited Talk]
* |
Masahito Togami (LINE) |
| |
13:55-14:05 |
Break ( 10 min. ) |
Wed, Mar 3 PM
14:05 - 15:35 |
(9)
EA |
14:05-15:35 |
[Poster Presentation]
A Study on active sinusoidal noise reduction system not requiring adaptive algorithm and secondary path filter |
Kensaku Fujii (Kodaway Lab.), Mitsuji Muneyasu (Kansai Univ.), Yoshifumi Chisaki (CIT) |
(10)
EA |
14:05-15:35 |
[Poster Presentation]
Issues on automatic soundscape generation based on image object detection |
Yoshifumi Chisaki (CIT), Toshiharu Horiuchi (KDDI Research, Inc.) |
(11)
EA |
14:05-15:35 |
[Poster Presentation]
A study of loudspeaker design for measuring near-field head-related transfer functions |
Atsuro Ito, Kentaro Matsui, Shu Kitajima (NHK) |
(12)
EA |
14:05-15:35 |
[Poster Presentation]
Subjective optimization of stereo width shrink algorithm in headphones reproduction |
Yui Ueno, Mitsunori Mizumachi (kyutech.), Toshiharu Horiuchi (KDDI Research, Inc.) |
(13)
SP |
14:05-15:35 |
[Poster Presentation]
A unified source-filter network for neural vocoder |
Reo Yoneyama, Yi-Chiao Wu, Tomoki Toda (Nagoya Univ.) |
(14)
SP |
14:05-15:35 |
[Poster Presentation]
Noise-robust time-domain speech separation with basis signals for noise |
Kohei Ozamoto (Tokyo Tech), Koji Iwano (TCU), Kuniaki Uto, Koichi Shinoda (Tokyo Tech) |
(15)
SP |
14:05-15:35 |
[Poster Presentation]
Investigation of DNN-based speech synthesis utilizing oral reading skills obtained from large scale subjective evaluation |
Shun Akui (UTokyo), Yusuke Ijima (NTT), Daisuke Saito, Nobuaki Minematsu (UTokyo) |
(16)
SP |
14:05-15:35 |
[Poster Presentation]
Psychological evaluation of popping-out voice quality |
Takashi Nakao, Tatsuya Kitamura (Konan Univ.) |
(17)
SP |
14:05-15:35 |
[Poster Presentation]
Comparison of speech intelligibility results between laboratory and crowd-sourcing experiments |
Ayako Yamamoto, Toshio Irino (Wakayama Univ.), Kenichi Arai, Shoko Araki, Atunori Ogawa, Keisuke Kinoshita, Tomohiro Nakatani (NTT) |
(18)
SP |
14:05-15:35 |
[Poster Presentation]
End-to-end incremental TTS with lookahead generation with large pretrained language model |
Takaaki Saeki, Shinnosuke Takamichi, Hiroshi Saruwatari (UTokyo) |
(19)
US |
14:05-15:35 |
[Poster Presentation]
The effect of periosteitis on the wave velocity in the third metatarsal bone
-- Comparison with healthy bone -- |
Sota Tanizawa, Kazuki Miyashita, Mineaki Takada (Doshisha Univ.), Norihisa Tamura, Hiroshi Mita (JRA), Mami Matsukawa (Doshisha Univ.) |
(20)
US |
14:05-15:35 |
[Poster Presentation]
Experimental evaluation of non-contact ultrasonic thickness gauging method using spatial frequency filter for inclined steel plate |
Shun Uemae (KU), Kazuki Abukawa, (NITKC), Tomoo Satoh, Sayuri Matsumoto (PARI), Kotaro Hoshiba, Takenobu Tsuchiya, Nobuyuki Endoh (KU) |
| |
15:35-15:45 |
Break ( 10 min. ) |
Wed, Mar 3 PM
15:45 - 16:35 |
(21)
SIP |
15:45-16:35 |
[Invited Talk]
Early Days of Adaptive Beamforming for Sound Acquisition |
Osamu Hoshuyama (Kyocera), Yutaka Kaneda (TDU) |
| |
16:35-16:45 |
Break ( 10 min. ) |
Wed, Mar 3 PM
16:45 - 18:00 |
(22)
SP |
16:45-17:10 |
An optimal prediction of phoneme under Bayes criterion by weighting multiple hidden Markov models |
Taishi Yamaoka, Shota Saito, Toshiyasu Matsushima (Waseda Univ.) |
(23)
SP |
17:10-17:35 |
An investigation of rhythm-based speaker embeddings for phoneme duration modeling |
Kenichi Fujita, Atsushi Ando, Yusuke Ijima (NTT) |
(24)
SP |
17:35-18:00 |
[Short Paper]
Comparison of End-to-End Models for Joint Speaker and Speech Recognition |
Kak Soky (Kyoto Univ.), Sheng Li (NICT), Masato Mimura, Chenhui Chu, Tatsuya Kawahara (Kyoto Univ.) |
Thu, Mar 4 AM
09:00 - 10:40 |
(25)
EA |
09:00-09:25 |
Anomalous Sound Detection Using a Binary Classification Model Considering Class Centroids |
Ibuki Kuroyanagi, Tomiki Hayashi, Kazuya Takeda, Tomoki Toda (Nagoya Univ) |
(26)
EA |
09:25-09:50 |
Development and Evaluation of Automatic Accompaniment System Using Foot Switch for Acoustical Signals |
Ryota Abe, Toshiyuki Kimura (Tohoku Gakuin Univ.) |
(27)
EA |
09:50-10:15 |
Subjective Evaluation of Recording System for Personal 3D Sound Field Reproduction |
Fumi Hanyu, Toshiyuki Kimura (Tohoku Gakuin Univ.) |
(28)
EA |
10:15-10:40 |
A quantitative measure of discriminability between NMF dictionaries |
Eisuke Konno, Daisuke Saito, Nobuaki Minematsu (UTokyo) |
| |
10:40-10:50 |
Break ( 10 min. ) |
Thu, Mar 4 AM
10:50 - 12:30 |
| (29) |
10:50-11:15 |
|
| (30) |
11:15-11:40 |
|
| (31) |
11:40-12:05 |
|
| (32) |
12:05-12:30 |
|
| |
12:30-13:30 |
Lunch Break ( 60 min. ) |
Thu, Mar 4 PM
13:30 - 14:20 |
| (33) |
13:30-14:20 |
|
| |
14:20-14:30 |
Break ( 10 min. ) |
Thu, Mar 4 PM
14:30 - 16:35 |
(34)
SIP |
14:30-14:55 |
Estimation of Attentional Direction using EEG during Simultaneous Presentation of Music from Two Sources |
Kana Mizokuchi, Toshihisa Tanaka (TUAT), Takashi G. Sato, Yoshifumi Shiraki (NTT) |
(35)
SIP |
14:55-15:20 |
Parameter estimation of an IIR sound correction system in a real environment |
Kento Kudo, Shinichi Inoue, Toshihisa Tanaka (TUAT) |
(36)
SIP |
15:20-15:45 |
Design of sparse IIR filters using LARS algorithm |
Yuki Shimozaki, Masayoshi Nakamoto (Hiroshima Univ.) |
(37)
SIP |
15:45-16:10 |
Nonlinear Modeling of Electro-dynamic Loudspeaker by Nonlinear IIR Filter |
Kenta Iwai, Takanobu Nishiura (Ritsumeikan Univ.) |
(38)
SIP |
16:10-16:35 |
Estimation of imagined speech from electrocorticogram with an encoder-decoder model |
Kotaro Hayashi, Shuji Komeiji (TUAT), Takumi Mitsuhashi, Yasushi Iimura, Hiroharu Suzuki, Hidenori Sugano (Juntendo Univ.), Koichi Shinoda (TokyoTech), Toshihisa Tanaka (TUAT) |
| |
16:35-16:45 |
Break ( 10 min. ) |
Thu, Mar 4 PM
16:45 - 17:35 |
(39)
SP |
16:45-17:10 |
Evaluation of Attention Fusion based Audio-Visual Target Speaker Extraction on Real Recordings |
Hiroshi Sato, Tsubasa Ochiai, Keisuke Kinoshita, Marc Delcroix, Tomohiro Nakatani, Shoko Araki (NTT) |
(40)
SP |
17:10-17:35 |
A Vocoder-free Any-to-Many Voice Conversion using Pre-trained vq-wav2vec |
Takeshi Koshizuka, Hidefumi Ohmura, Kouichi Katsurada (TUS) |
| |
17:35-17:45 |
Break ( 10 min. ) |
Thu, Mar 4 PM
17:45 - 18:05 |
| (41) |
17:45-18:05 |
|


 i
i
 : d
: d